

Tags
- Tree
- count
- drf
- distinct
- delete
- 완전검색
- stack
- Article & User
- ORM
- create
- 백트래킹
- DB
- update
- N:1
- regexp
- Queue
- migrations
- 스택
- 뷰
- SQL
- outer join
- 큐
- 통계학
- M:N
- 그리디
- 쟝고
- Django
- Vue
- 트리
- 이진트리
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Notice
Recent Posts
Link
데이터 분석 기술 블로그
VARIANCE 함수 본문
VARIANCE 함수란?
"VARIANCE" 함수는 데이터 집합의 분산(Variance)을 계산하는 데 사용됩니다. 분산은 데이터가 평균을 중심으로 얼마나 퍼져 있는지를 나타내는 통계적 척도입니다.
분산의 정의

VARIANCE 함수의 구문
SELECT VARIANCE(column_name)
FROM table_name;- column_name: 분산을 계산할 열의 이름.
- table_name: 데이터를 포함한 테이블 이름.
분산 계산의 두 가지의 유형
- 모분산 (Population Variance):
- 전체 데이터 집합을 기준으로 분산을 계산.
- SQL에서 기본적으로 제공되는 VARIANCE 함수는 모분산을 계산합니다.
- 표본분산 (Sample Variance):
- 데이터 집합의 일부를 기반으로 분산을 계산.
- SQL에서 VAR_SAMP를 사용하면 표본분산을 계산할 수 있습니다.
예시
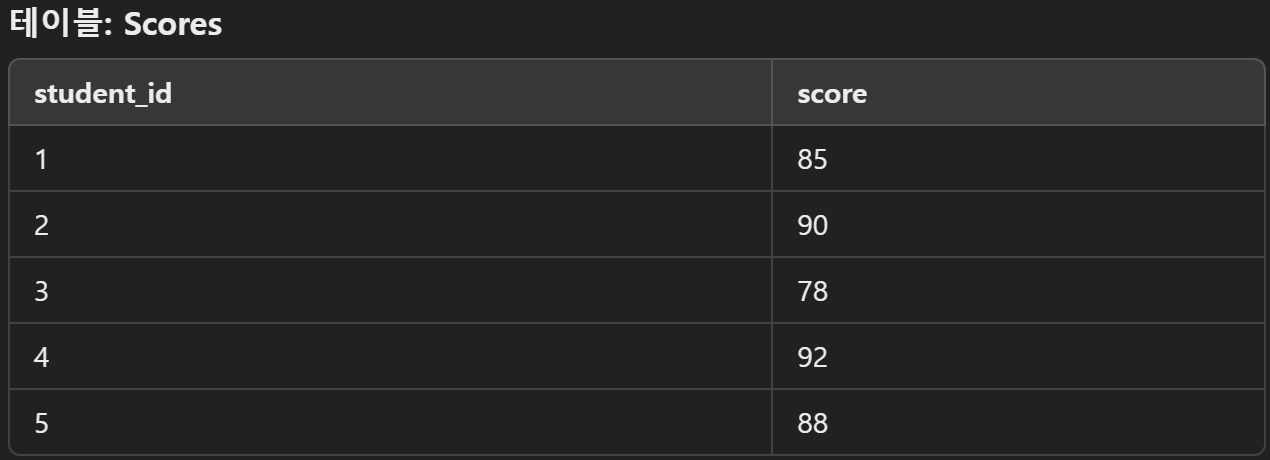
문제: 모든 학생의 점수 분산을 계산하려면?
SELECT VARIANCE(score) AS score_variance
FROM Scores;
'SQL > 개념' 카테고리의 다른 글
| CONCAT 함수 (0) | 2024.11.07 |
|---|---|
| ROUND 함수 (0) | 2024.11.06 |
| DISTINCT 키워드 (0) | 2024.11.04 |
| GROUP BY 절 (0) | 2024.11.03 |
| HAVING 절 (0) | 2024.09.13 |
'SQL/개념' Related Articles
more



