

- Vue
- 스택
- DB
- ORM
- distinct
- regexp
- M:N
- 백트래킹
- 쟝고
- create
- N:1
- Django
- SQL
- update
- Tree
- drf
- delete
- outer join
- Queue
- 이진트리
- count
- stack
- 통계학
- 큐
- 트리
- 그리디
- Article & User
- migrations
- 뷰
- 완전검색
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
데이터 분석 기술 블로그
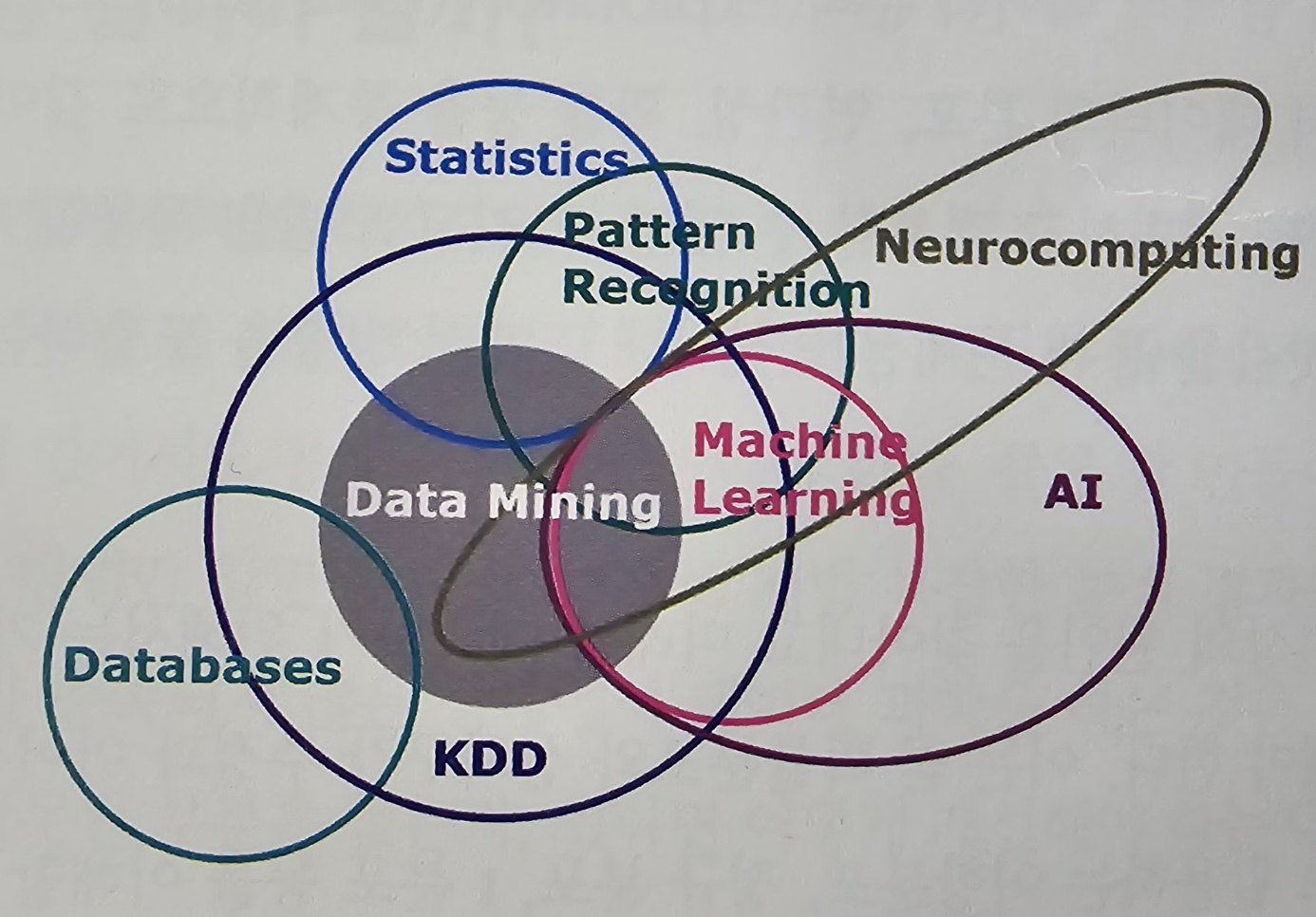
2. 머신러닝과 통계학의 차이 본문
머신러닝과 통계학의 큰 차이점 중 하나는 머신러닝은 예측(Prediction)이 목적이고 통계학은 해석(explanation)이 목적입니다.
머신러닝은 '예측력이 얼마나 높은가'가 중요합니다. 예를 들어 특정한 사진을 얼마나 정확히 구별하는지 또는 고객의 구매를 얼마나 정확하게 예측하는지에 집중합니다. 따라서 머신러닝은 분석 모형의 복잡성(complexity)이 높고, 과적합(overfitting) 해결이 중요합니다. 여기서 overfitting이란, 학습 데이터를 과하게 학습해서 예측 데이터에 대한 정확도가 감소하는 현상입니다.
복잡성과 과적합의 중요성을 알려주는 좋은 예시가 있습니다. 미국의 OTT 서비스 업체 넷프릭스가 영화 추천 시스템 개선 알고리즘 대회(상금이 무려 100만 달러였습니다.)를 열었습니다. 상금 지급 기준은 기존 넷플릭스영화 추천시스템보다 10% 이상 개선된 성능을 보이는 팀이었습니다. 많은 팀들이 10% 이상 개선을 보였지만 모델 자체가 워낙 복잡하고 비효율적이며, 해석이 불가능해서 실제 시스템에는 적용하지 못했습니다.
통계학은 모델의 신뢰도를 중요시하고 복잡성보다는 단순성에 초점을 맞춥니다. 각 변수의 영향력에 대한 해석과 모집단에서 추출한 샘플의 가정(Assumption)과 통계적 적합성에 집중합니다. 따라서 통계학은 확률을 통해 가설을 검증하고 추정 모델을 통해 데이터를 해석하는 데에 목적을 둡니다. 이러한 통계학의 확률적 이론과 에러를 최소화하는 원리는 머신러닝, 데이터 과학의 기초가 됩니다.
현대의 머신러닝은 단순한 데이터 학습을 넘어 예측까지 나아갑니다. 데이터는 계속해서 증가하고 변화하기 때문에 이를 고려해서 학습과 예측 프로세스를 설계하는 것도 머신러닝으로 봅니다. 즉, 진정한 머신러닝은 데이터의 학습과 분류, 예측을 자체를 학습하도록 프로그래밍된 것입니다. 이는 이후 설명할 딥러닝(deep learning)과 강화 학습(reinforcement learning)과 관련이 있습니다.
| 통계학 | 머신러닝 | |
| 접근 방식 | 확률변수를 통해 자료생성과정(Data Generating Process: DGP)을 파악 | 알고리즘 모델을 생성 |
| 기반 | 수학, 이론 | 비선형 데이터 피팅(Data fitting) |
| 목표 | 가설 검정, 현상 해석 | 예측 정확도 향상 |
| 변수(차원) | 10개 이하의 소수 변수 활용 | 다차원의 변수 활용 |
| 활용 | 과거와 현재 데이터를 활용한 현상의 해석 | 과거와 현재 데이터를 활용한 미래 예측 |
| 접근 방향 | 가설 → 데이터 | 데이터 → 가설 |
'데이터 분석' 카테고리의 다른 글
| 6. 모집단과 표본, 전수조사와 표본조사 (0) | 2024.08.03 |
|---|---|
| 5. 기술 통계와 추론 통계 : 추론 통계 (0) | 2024.08.02 |
| 4. 기술 통계와 추론 통계 : 기술 통계 (0) | 2024.08.01 |
| 3. 통계학의 정의와 기원 (0) | 2024.07.31 |
| 1. 통계학을 알아야 하는 이유 (0) | 2024.07.29 |


