

Tags
- 백트래킹
- N:1
- stack
- ORM
- 이진트리
- 스택
- 완전검색
- migrations
- 트리
- 그리디
- DB
- M:N
- Article & User
- SQL
- 통계학
- 뷰
- 큐
- Queue
- delete
- outer join
- regexp
- distinct
- count
- Django
- 쟝고
- drf
- update
- Tree
- create
- Vue
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
Notice
Recent Posts
Link
데이터 분석 기술 블로그
너비 우선 탐색 (BFS, Breadth-First Search) 본문
너비 우선 탐색 BFS
"그래프 탐색 기법 중 하나로, 가까운 노드부터 차례대로 탐색하는 방식"
- 큐(Queue)를 사용하여 구현
- 한 단계씩 확장하며 탐색 → 최단 경로 문제에서 유용함
- DFS(깊이 우선 탐색)와 달리, 모든 노드를 동일한 깊이(레벨)에서 먼저 탐색
BFS 동작 원리
- 시작 노드를 큐(Queue)에 삽입하고 방문 처리
- 큐에서 노드를 꺼내고, 인접한 노드를 모두 큐에 삽입
- 큐가 빌 때까지 위 과정을 반복
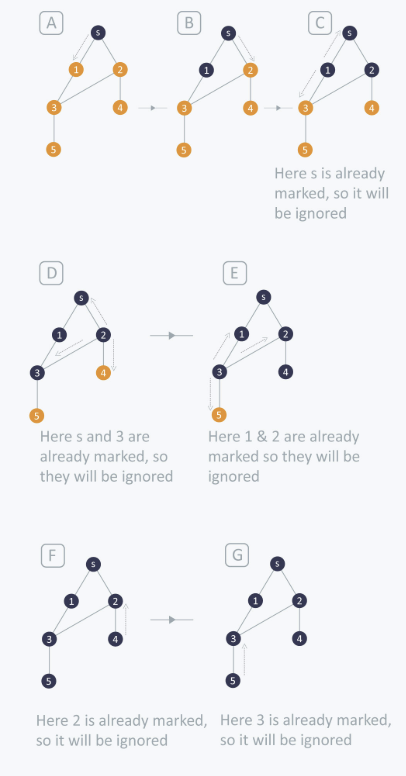
# Pseudo Code
FUNCTION DFS(node):
방문[node] = True # 현재 노드를 방문 처리
출력(node) # 노드 방문
FOR 모든 인접 노드 in node의 이웃 리스트:
IF 방문[인접 노드] == False THEN
DFS(인접 노드) # 재귀 호출
# 재귀 기반
def dfs(graph, node, visited):
if visited[node]: # 이미 방문한 노드라면 리턴
return
visited[node] = True # 현재 노드 방문 처리
print(node, end=' ') # 방문한 노드 출력
for neighbor in graph[node]: # 인접 노드 탐색
if not visited[neighbor]:
dfs(graph, neighbor, visited) # 재귀 호출
# 그래프 (인접 리스트 표현)
graph = {
1: [2, 3],
2: [4, 5],
3: [6],
4: [],
5: [],
6: []
}
visited = {key: False for key in graph} # 방문 기록 초기화
dfs(graph, 1, visited)
# 스택 기반
def dfs_iterative(graph, start):
stack = [start] # 스택을 사용하여 DFS 구현
visited = {key: False for key in graph} # 방문 기록 초기화
while stack:
node = stack.pop() # 스택에서 하나 꺼내기
if not visited[node]: # 방문하지 않았다면
print(node, end=' ') # 노드 출력
visited[node] = True # 방문 처리
stack.extend(reversed(graph[node])) # 인접 노드 추가 (순서를 유지하기 위해 reverse)
# 그래프 (인접 리스트 표현)
graph = {
1: [2, 3],
2: [4, 5],
3: [6],
4: [],
5: [],
6: []
}
dfs_iterative(graph, 1)DFS의 시간복잡도
| 경우 | 시간복잡도 |
| 그래프(V = 노드, E = 간선) | O(V + E) |
| 트리(N = 노드 개수) | O(N) |
✅ 모든 노드를 방문하므로 O(V + E) (그래프)
✅ 트리에서는 O(N), 연결 리스트에서는 O(N)
DFS의 장단점
장점
- 최단 경로(Shortest Path) 문제에서 최적解 제공 (가중치 없는 그래프)
- 모든 노드를 동일한 깊이에서 탐색 → 특정 조건을 만족하는 첫 번째 노드를 빠르게 찾을 때 유리
- DFS보다 스택 오버플로우 발생 가능성이 낮음 (큐 기반이므로 깊이 제한 없음)
단점
- 큐(Queue)를 사용하므로 메모리 사용량이 큼 (O(V))
- 경우에 따라 탐색 속도가 DFS보다 느릴 수 있음
- 가중치가 있는 그래프에서는 다익스트라 알고리즘이 더 적절함
결론
BFS는 가까운 노드부터 차례로 탐색하는 방식이며, 최단 경로 문제나 특정 조건을 만족하는 첫 번째 노드를 찾는 데 유용하다.
'데이터 사이언스 > 알고리즘' 카테고리의 다른 글
| 벨만-포드 알고리즘(Bellman-Ford Algorithm) (0) | 2025.02.26 |
|---|---|
| 다익스트라 알고리즘(Dijkstra's Algorithm) (0) | 2025.02.25 |
| 깊이 우선 탐색 (DFS, Depth-First Search) (0) | 2025.02.23 |
| 이진 탐색(Binary Search) (0) | 2025.02.22 |
| 선형 탐색(Linear Search) (0) | 2025.02.21 |
'데이터 사이언스/알고리즘' Related Articles
more



